- 대회설명: 1시간 전의 기상상황을 가지고 1시간 후의 따릉이 대여수를 예측
- 대회일자: 2019.09.09 ~ 2019.10.05
- 주관: Dacon
- 수상실적: 1위
모듈 및 파일 로드
from google.colab import drive
drive.mount('/gdrive', force_remount=True)
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
train_raw = pd.read_csv('/gdrive/My Drive/train.csv', encoding='utf-8')
test_raw = pd.read_csv('/gdrive/My Drive/test.csv', encoding = 'utf-8')
##EDA 및 Data Preprocessing
train_raw.head(5)
| id | hour | hour_bef_temperature | hour_bef_precipitation | hour_bef_windspeed | hour_bef_humidity | hour_bef_visibility | hour_bef_ozone | hour_bef_pm10 | hour_bef_pm2.5 | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 20 | 16.3 | 1.0 | 1.5 | 89.0 | 576.0 | 0.027 | 76.0 | 33.0 | 49.0 |
| 1 | 6 | 13 | 20.1 | 0.0 | 1.4 | 48.0 | 916.0 | 0.042 | 73.0 | 40.0 | 159.0 |
| 2 | 7 | 6 | 13.9 | 0.0 | 0.7 | 79.0 | 1382.0 | 0.033 | 32.0 | 19.0 | 26.0 |
| 3 | 8 | 23 | 8.1 | 0.0 | 2.7 | 54.0 | 946.0 | 0.040 | 75.0 | 64.0 | 57.0 |
| 4 | 9 | 18 | 29.5 | 0.0 | 4.8 | 7.0 | 2000.0 | 0.057 | 27.0 | 11.0 | 431.0 |
train_raw.isnull().sum()
id 0
hour 0
hour_bef_temperature 2
hour_bef_precipitation 2
hour_bef_windspeed 9
hour_bef_humidity 2
hour_bef_visibility 2
hour_bef_ozone 76
hour_bef_pm10 90
hour_bef_pm2.5 117
count 0
dtype: int64
# 결측치 분석
train_raw.loc[train_raw['hour_bef_temperature'].isnull()]
| id | hour | hour_bef_temperature | hour_bef_precipitation | hour_bef_windspeed | hour_bef_humidity | hour_bef_visibility | hour_bef_ozone | hour_bef_pm10 | hour_bef_pm2.5 | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 934 | 1420 | 0 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 39.0 |
| 1035 | 1553 | 18 | NaN | NaN | NaN | NaN | NaN | NaN | NaN | NaN | 1.0 |
# 결측치 분석 결과 아무런 정보를 갖지 않는 data point인 것을 확인 후 제거
train = train_raw.loc[train_raw['hour_bef_temperature'].notnull()]
train.isnull().sum()
id 0
hour 0
hour_bef_temperature 0
hour_bef_precipitation 0
hour_bef_windspeed 7
hour_bef_humidity 0
hour_bef_visibility 0
hour_bef_ozone 74
hour_bef_pm10 88
hour_bef_pm2.5 115
count 0
dtype: int64
train.describe()
| id | hour | hour_bef_temperature | hour_bef_precipitation | hour_bef_windspeed | hour_bef_humidity | hour_bef_visibility | hour_bef_ozone | hour_bef_pm10 | hour_bef_pm2.5 | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 1457.000000 | 1457.000000 | 1457.000000 | 1457.000000 | 1450.000000 | 1457.000000 | 1457.000000 | 1383.000000 | 1369.000000 | 1342.000000 | 1457.000000 |
| mean | 1105.391901 | 11.496911 | 16.717433 | 0.031572 | 2.479034 | 52.231297 | 1405.216884 | 0.039149 | 57.168736 | 30.327124 | 108.684969 |
| std | 631.609634 | 6.918890 | 5.239150 | 0.174917 | 1.378265 | 20.370387 | 583.131708 | 0.019509 | 31.771019 | 14.713252 | 82.620202 |
| min | 3.000000 | 0.000000 | 3.100000 | 0.000000 | 0.000000 | 7.000000 | 78.000000 | 0.003000 | 9.000000 | 8.000000 | 1.000000 |
| 25% | 555.000000 | 6.000000 | 12.800000 | 0.000000 | 1.400000 | 36.000000 | 879.000000 | 0.025500 | 36.000000 | 20.000000 | 37.000000 |
| 50% | 1113.000000 | 11.000000 | 16.600000 | 0.000000 | 2.300000 | 51.000000 | 1577.000000 | 0.039000 | 51.000000 | 26.000000 | 96.000000 |
| 75% | 1652.000000 | 17.000000 | 20.100000 | 0.000000 | 3.400000 | 69.000000 | 1994.000000 | 0.052000 | 69.000000 | 37.000000 | 150.000000 |
| max | 2179.000000 | 23.000000 | 30.000000 | 1.000000 | 8.000000 | 99.000000 | 2000.000000 | 0.125000 | 269.000000 | 90.000000 | 431.000000 |
train.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 1457 entries, 0 to 1458
Data columns (total 11 columns):
id 1457 non-null int64
hour 1457 non-null int64
hour_bef_temperature 1457 non-null float64
hour_bef_precipitation 1457 non-null float64
hour_bef_windspeed 1450 non-null float64
hour_bef_humidity 1457 non-null float64
hour_bef_visibility 1457 non-null float64
hour_bef_ozone 1383 non-null float64
hour_bef_pm10 1369 non-null float64
hour_bef_pm2.5 1342 non-null float64
count 1457 non-null float64
dtypes: float64(9), int64(2)
memory usage: 136.6 KB
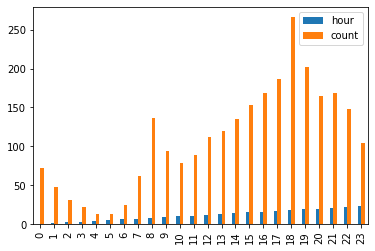
# 시간에 따른 이용량 시각화
train.groupby(['hour'], as_index = False)['count'].mean().plot.bar()
<matplotlib.axes._subplots.AxesSubplot at 0x7f0b6a378128>
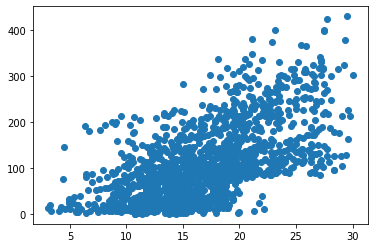
# 1시간전 기온에 따른 이용량 분석
plt.scatter(train['hour_bef_temperature'], train['count'])
train[['hour_bef_temperature', 'count']].corr(method = 'pearson')
| hour_bef_temperature | count | |
|---|---|---|
| hour_bef_temperature | 1.000000 | 0.619404 |
| count | 0.619404 | 1.000000 |
# 강수 유무에 따른 이용량 분석
train.groupby(['hour_bef_precipitation'])['count'].mean()
hour_bef_precipitation
0.0 111.130404
1.0 33.673913
Name: count, dtype: float64
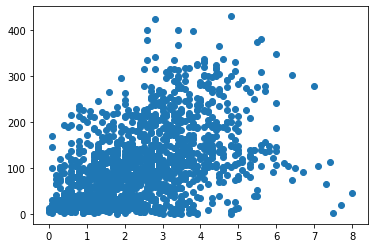
# 바람세기에 따른 이용량 분석
plt.scatter(train['hour_bef_windspeed'], train['count'])
train[['hour_bef_windspeed', 'count']].corr(method = 'pearson')
| hour_bef_windspeed | count | |
|---|---|---|
| hour_bef_windspeed | 1.000000 | 0.459906 |
| count | 0.459906 | 1.000000 |
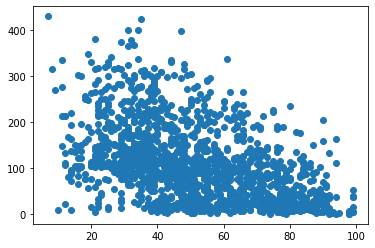
# 습도에 따른 이용량 분석
plt.scatter(train['hour_bef_humidity'], train['count'])
train[['hour_bef_humidity', 'count']].corr(method = 'pearson')
| hour_bef_humidity | count | |
|---|---|---|
| hour_bef_humidity | 1.000000 | -0.471142 |
| count | -0.471142 | 1.000000 |
# 가시성에 따른 이용량 분석
plt.scatter(train['hour_bef_visibility'], train['count'])
train[['hour_bef_visibility', 'count']].corr(method = 'pearson')
| hour_bef_visibility | count | |
|---|---|---|
| hour_bef_visibility | 1.000000 | 0.299094 |
| count | 0.299094 | 1.000000 |
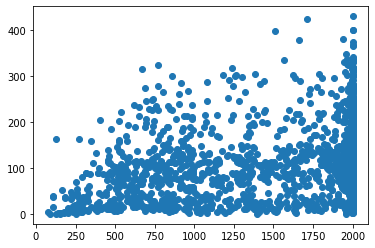
# 오존량에 따른 이용량 분석
plt.scatter(train['hour_bef_ozone'], train['count'])
train[['hour_bef_ozone', 'count']].corr(method = 'pearson')
| hour_bef_ozone | count | |
|---|---|---|
| hour_bef_ozone | 1.000000 | 0.477614 |
| count | 0.477614 | 1.000000 |
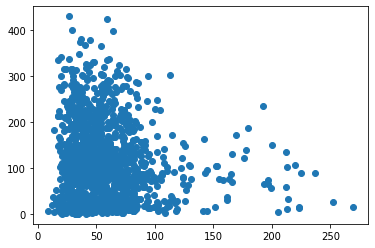
# pm10에 따른 이용량 분석
plt.scatter(train['hour_bef_pm10'], train['count'])
train[['hour_bef_pm10', 'count']].corr(method = 'pearson')
| hour_bef_pm10 | count | |
|---|---|---|
| hour_bef_pm10 | 1.000000 | -0.114288 |
| count | -0.114288 | 1.000000 |
# pm2.5에 따른 이용량 분석
plt.scatter(train['hour_bef_pm2.5'], train['count'])
train[['hour_bef_pm2.5', 'count']].corr(method = 'pearson')
| hour_bef_pm2.5 | count | |
|---|---|---|
| hour_bef_pm2.5 | 1.000000 | -0.134293 |
| count | -0.134293 | 1.000000 |
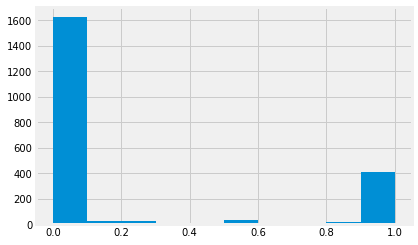
# 오존농도를 기상청에서 알려주는 좋음/보통/나쁨/매우나쁨 을 기준으로 다른 class 부여
train['hour_bef_ozone'] = train['hour_bef_ozone'].apply(lambda x : 0 if x <= 0.03 else
1 if 0.03 < x and x <= 0.09 else
2 if 0.09 < x and x <= 0.151 else
3 if 0.151 < x else x)
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
"""Entry point for launching an IPython kernel.
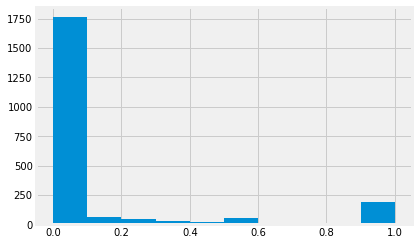
# 미세먼지를 기상청에서 알려주는 좋음/보통/나쁨/매우나쁨 을 기준으로 다른 class 부여
train['hour_bef_pm10'] = train['hour_bef_pm10'].apply(lambda x : 0 if x <= 30 else
1 if 30 < x and x <= 80 else
2 if 80 < x and x <= 150 else
3 if 150 < x else x)
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
"""Entry point for launching an IPython kernel.
# 초미세먼지를 기상청에서 알려주는 좋음/보통/나쁨/매우나쁨 을 기준으로 다른 class 부여
train['hour_bef_pm2.5'] = train['hour_bef_pm2.5'].apply(lambda x : 0 if x <= 15 else
1 if 15 < x and x <= 35 else
2 if 35 < x and x <= 75 else
3 if 75 < x else x)
/usr/local/lib/python3.6/dist-packages/ipykernel_launcher.py:1: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame.
Try using .loc[row_indexer,col_indexer] = value instead
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
"""Entry point for launching an IPython kernel.
train.median(axis = 0)
id 1113.0
hour 11.0
hour_bef_temperature 16.6
hour_bef_precipitation 0.0
hour_bef_windspeed 2.3
hour_bef_humidity 51.0
hour_bef_visibility 1577.0
hour_bef_ozone 1.0
hour_bef_pm10 1.0
hour_bef_pm2.5 1.0
count 96.0
dtype: float64
# 결측치를 median 값으로 처리
train.fillna(train.median(), inplace = True)
/usr/local/lib/python3.6/dist-packages/pandas/core/generic.py:6287: SettingWithCopyWarning:
A value is trying to be set on a copy of a slice from a DataFrame
See the caveats in the documentation: http://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
self._update_inplace(new_data)
# train data 확인
train.isnull().sum()
id 0
hour 0
hour_bef_temperature 0
hour_bef_precipitation 0
hour_bef_windspeed 0
hour_bef_humidity 0
hour_bef_visibility 0
hour_bef_ozone 0
hour_bef_pm10 0
hour_bef_pm2.5 0
count 0
dtype: int64
# train data 확인
train.head(3)
| id | hour | hour_bef_temperature | hour_bef_precipitation | hour_bef_windspeed | hour_bef_humidity | hour_bef_visibility | hour_bef_ozone | hour_bef_pm10 | hour_bef_pm2.5 | count | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 3 | 20 | 16.3 | 1.0 | 1.5 | 89.0 | 576.0 | 0.0 | 1.0 | 1.0 | 49.0 |
| 1 | 6 | 13 | 20.1 | 0.0 | 1.4 | 48.0 | 916.0 | 1.0 | 1.0 | 2.0 | 159.0 |
| 2 | 7 | 6 | 13.9 | 0.0 | 0.7 | 79.0 | 1382.0 | 1.0 | 1.0 | 1.0 | 26.0 |
# train data set의 id값 제거, count 값 분리, array형태 변환
train_x = np.array(train.iloc[:, 1:-1])
train_y = np.array(train.iloc[:, 0])
Modeling
# 모듈설치
from sklearn.linear_model import Lasso
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from xgboost import XGBRegressor
import xgboost as xgb
import lightgbm as lgb
from sklearn.svm import SVR
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import KFold
from sklearn.model_selection import cross_val_score
from sklearn.metrics import mean_squared_error
# 모델별 rmse를 확인하는 함수
def rmse(model):
kf = KFold(10, shuffle = True, random_state = 42)
rmse = np.sqrt(-cross_val_score(model, train_x, train_y, scoring = 'neg_mean_squared_error', cv = kf))
print(np.mean(rmse))
# 모델별 hyperparameter에 따른 rmse를 확인하는 함수
def girds(model, hyperparameters):
kf = KFold(10, shuffle = True, random_state = 42)
grid_search = GridSearchCV(model, param_grid = hyperparameters, scoring = 'neg_mean_squared_error', cv = kf)
grid_search.fit(train_x, train_y)
grid_search_result = grid_search.cv_results_
for mean_score, params in zip(grid_search_result['mean_test_score'], grid_search_result['params']):
print(np.sqrt(-mean_score), params)
# 최종 제출본 만들기
def submission(prediction):
sub = pd.DataFrame()
sub['id'] = test['id']
sub['pred'] = prediction
sub.to_csv('submission.csv', index = False)
lasso = make_pipeline(RobustScaler(), Lasso(random_state=3))
lasso_params = {'lasso__alpha' : [0.0001, 0.001, 0.01, 0.1]}
girds(lasso, lasso_params)
52.75776537898072 {'lasso__alpha': 0.0001}
52.75762990190659 {'lasso__alpha': 0.001}
52.75632230762074 {'lasso__alpha': 0.01}
52.74969915001244 {'lasso__alpha': 0.1}
model_GBoost = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state =5)
rmse(model_GBoost)
39.93306739247525
model_rf = RandomForestRegressor()
rf_params = {'n_estimators': [3, 10, 30, 60, 90]}
girds(model_rf, rf_params)
/usr/local/lib/python3.6/dist-packages/sklearn/model_selection/_search.py:814: DeprecationWarning: The default of the `iid` parameter will change from True to False in version 0.22 and will be removed in 0.24. This will change numeric results when test-set sizes are unequal.
DeprecationWarning)
43.87376948585613 {'n_estimators': 3}
39.77442736314237 {'n_estimators': 10}
39.145458200601915 {'n_estimators': 30}
38.71933540674437 {'n_estimators': 60}
38.703951845692636 {'n_estimators': 90}
model_lgb = lgb.LGBMRegressor()
rmse(model_lgb)
38.22539983547282
model_xgb = xgb.XGBRegressor()
rmse(model_xgb)
[07:38:56] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
[07:38:56] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
[07:38:56] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
[07:38:56] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
[07:38:57] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
[07:38:57] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
[07:38:57] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
[07:38:57] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
[07:38:57] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
[07:38:57] WARNING: /workspace/src/objective/regression_obj.cu:152: reg:linear is now deprecated in favor of reg:squarederror.
39.275307376492854
# 가장 성능이 좋은 3개의 model을 선정해 학습
model_rf = RandomForestRegressor(n_estimators = 90)
model_rf.fit(train_x, train_y)
model_xgb = xgb.XGBRegressor()
model_xgb.fit(train_x, train_y)
model_lgb = lgb.LGBMRegressor()
model_lgb.fit(train_x, train_y)
# test data set 처리
test_raw['hour_bef_ozone'] = test_raw['hour_bef_ozone'].apply(lambda x : 0 if x <= 0.03 else
1 if 0.03 < x and x <= 0.09 else
2 if 0.09 < x and x <= 0.151 else
3 if 0.151 < x else x)
test_raw['hour_bef_pm10'] = test_raw['hour_bef_pm10'].apply(lambda x : 0 if x <= 30 else
1 if 30 < x and x <= 80 else
2 if 80 < x and x <= 150 else
3 if 150 < x else x)
test_raw['hour_bef_pm2.5'] = test_raw['hour_bef_pm2.5'].apply(lambda x : 0 if x <= 15 else
1 if 15 < x and x <= 35 else
2 if 35 < x and x <= 75 else
3 if 75 < x else x)
test = test_raw.fillna(train.median())
test_x = np.array(test.iloc[:, 1:])
print(test_x[0,0])
# 3개의 모델을 적절한 비율로 ensemble하여 predict
ensemble = model_rf.predict(test_x) * 0.25 + model_lgb.predict(test_x) * 0.5 + model_xgb.predict(test_x) * 0.25
submission(ensemble)