- 프로젝트 설명: 강화학습을 이용한 농구 전략 탐색하기
- 공모전 일자: 2020.05 ~ 2020.07
- 주관: 성균관대학교 대학혁신과공유센터
- 수상실적: TBD
강화학습을 이용한 농구 전략 탐색하기
연구 배경 및 목적
- 현대 스포츠는 다양한 방면에서 데이터를 수집하고 있고 이러한 데이터를 활용하여 스포츠의 많은 부분에 도움을 주고 있다. 미국 프로농구 팀에서는 데이터 분석가를 고용하고 이를 활용하여 선수들을 평가하고 전략 수립에 간접적인 도움을 받고 있다.
- 하지만 데이터를 활용한 딥러닝 방식으로는 직접적인 전략 생성에 어려움이 있다.
- 우리는 이러한 점을 타개하기 위해 강화학습 방법을 사용하여 농구전략을 생성해 내는 모델을 만들 것이다.
연구 배경지식
- 강화학습이란
- 강화학습이란 어떠한 환경 안에서 정의된 에이전트가 현재의 상태를 인식하여 선택 가능한 행동 들 중 최종 보상을 제일 크게 하는 행동들의 집합인 정책을 스스로 학습하게 하는 기계학습의 한 영역이다.
- PPO
- 기존의 목적함수 대신 minibatch update의 multiple epochs를 가능하게 만들어 주는 대체목적함수를 사용하고 이를 최적화 하는 알고리즘이다 .
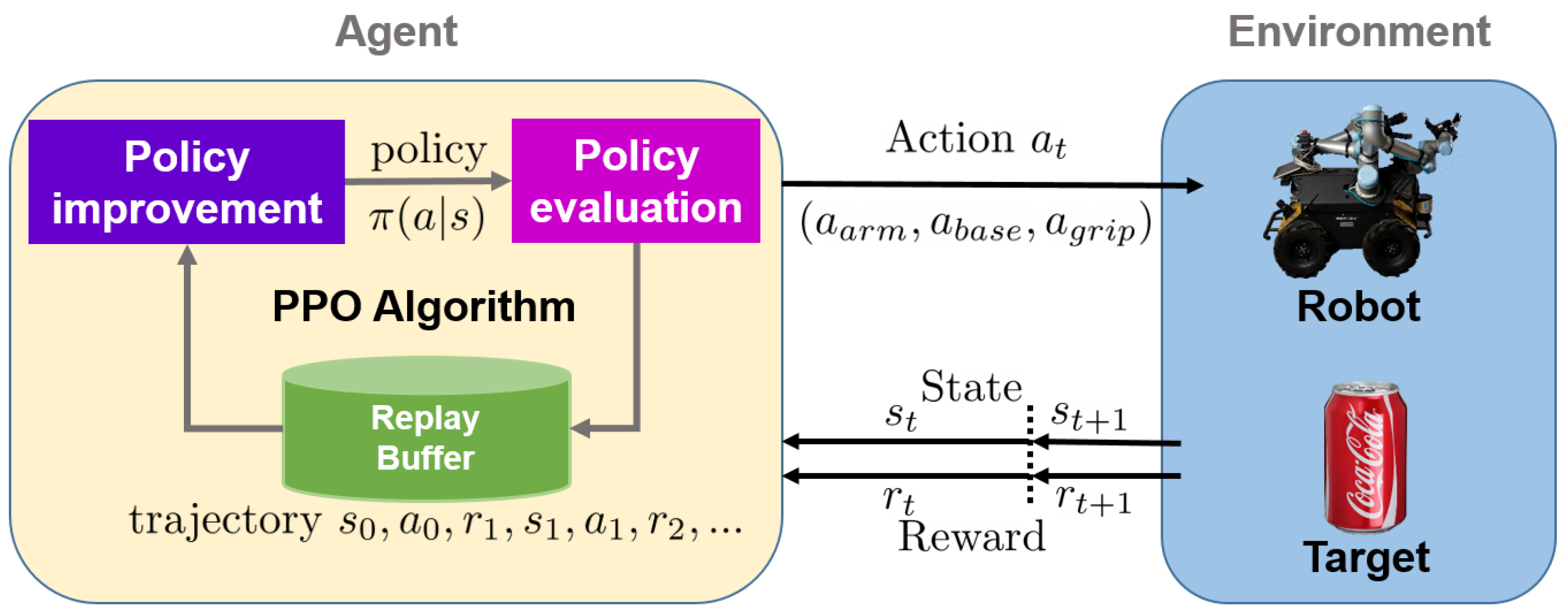
출처 : Wang, C., Zhang, Q., Tian, Q., Li, S., Wang, X., Lane, D., … & Wang, S. (2020). Learning Mobile Manipulation through Deep Reinforcement Learning. Sensors, 20(3), 939.
연구 Task
- 기존 농구 전략 관련 연구의 한계점
- 농구 전략 관련 연구는 최적화된 전략을 제시하는 것이 아닌, 단순히 다음 행동을 예측하는 것에 그치고 있다.
- 새로운 환경의 필요성
- 이는 그러한 모델을 학습할 환경이 부재하였기 때문이였다.
- 기존에 있는 농구 모델 환경( EndtoendAI Atari Double Env : Atari Double Dunk Environment, Fever Basketball)은 5대 5가 아닌 3대 3의 경기만을 표현하는 환경이였고 또한 선수들의 능력치를 넣을 수 없는 환경이였다.
- 이에 우리는 새로운 농구 경기 환경을 만들기로 했다.
- Exploration 문제
- 선수들이 여러 지역을 탐색하면서 최적의 전략을 탐색해야 하지만 단순히 Entropy-bonus만 가지고 탐색이 어려워 직접 에이전트를 위치를 이동시켜 탐색을 진행하게 하였다.
연구 진행
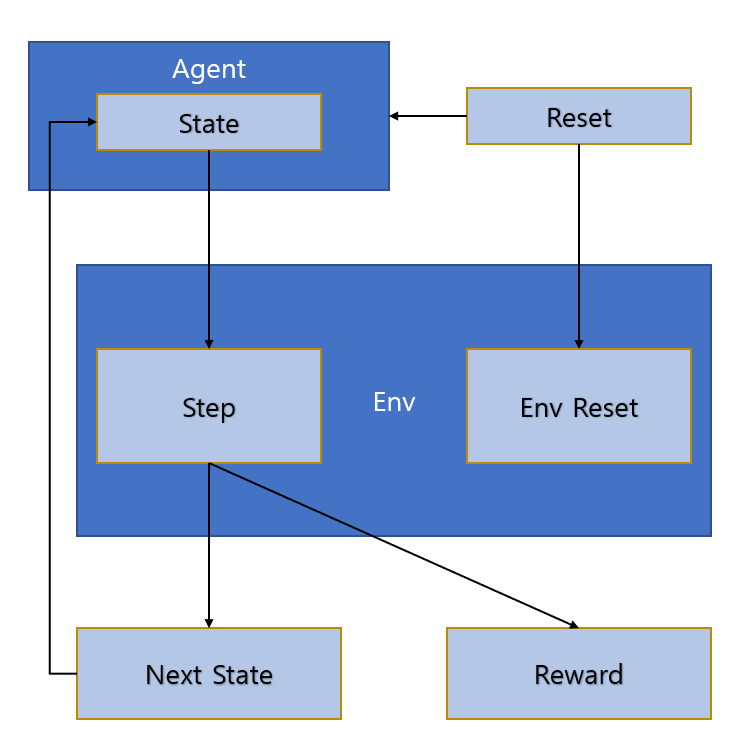
- 환경 만들기
-
환경은 Open AI의 Gym의 작동 방식을 가져와서 만들었다.
-
- 환경 시각화
-
환경 시각화는 matplotlib를 동영상으로 만들어주는 celluloid라는 라이브러리를 이용하여 시각화를 진행하였다.
-
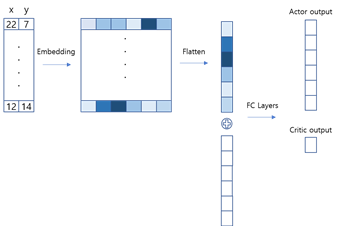
- 강화학습 방식 및 네트워크 구조
- 강화학습 모델은 Actor-critic방식 중에 PPO방식을 사용하여 학습을 진행 하였다.
- 네트워크 구조는 아래의 그림과 같다.
실험 결과
농구 전략의 우수성을 평가하는 객관적인 지표가 존재하지 않고 생성 모델을 정략적으로 평가하기 어려워 test과정에서 나오는 대표적인 사례를 가져와 분석하였다.
- 공격수가 파고드는 상황
-
외각지역의 공격수가 파고든 공격 선수한테 패스하는 상황
-
들어오려는 공격수를 압박하는 수비수
연구 의의 및 한계점
본 연구는 새로운 농구 환경을 만들고 유의미한 결과까지 도출 했다는 것에 의의를 들 수 있다. 하지만 정략적인 평가가 부족하였고 1번의 공격기회만을 두고 경기를 진행하였기 때문에 좀 더 여러번의 공격기회를 가질 수 있게 수정하면 좀 더 좋은 전략을 구사할 수 있을 것으로 기대가 된다.